Interactive online version:
![]()
Working With Sessions
Import the LArray library:
[2]:
from larray import *
Three Kinds Of Sessions
They are three ways to group objects in LArray:
Session: is an ordered dict-like container with special I/O methods. Although the autocomplete* feature on the objects stored in the session is available in the larray-editor, it is not available in development tools like PyCharm making it cumbersome to use.
CheckedSession: provides the same methods as Session objects but are defined in a completely different way (see example below). The autocomplete* feature is both available in the larray-editor and in development tools (PyCharm). In addition, the type of each stored object is protected. Optionally, it is possible to constrain the axes and dtype of arrays using
CheckedArray.CheckedParameters: is a special version of CheckedSession in which the value of all stored objects (parameters) is frozen after initialization.
* Autocomplete is the feature in which development tools try to predict the variable or function a user intends to enter after only a few characters have been typed (like word completion in cell phones).
Creating Sessions
Session
Create a session:
[3]:
# define some scalars, axes and arrays
variant = 'baseline'
country = Axis('country=Belgium,France,Germany')
gender = Axis('gender=Male,Female')
time = Axis('time=2013..2017')
population = zeros([country, gender, time])
births = zeros([country, gender, time])
deaths = zeros([country, gender, time])
[4]:
# create an empty session and objects one by one after
s = Session()
s.variant = variant
s.country = country
s.gender = gender
s.time = time
s.population = population
s.births = births
s.deaths = deaths
print(s.summary())
variant: baseline
country: country ['Belgium' 'France' 'Germany'] (3)
gender: gender ['Male' 'Female'] (2)
time: time [2013 2014 2015 2016 2017] (5)
population: country, gender, time (3 x 2 x 5) [float64]
births: country, gender, time (3 x 2 x 5) [float64]
deaths: country, gender, time (3 x 2 x 5) [float64]
[5]:
# or create a session in one step by passing all objects to the constructor
s = Session(variant=variant, country=country, gender=gender, time=time,
population=population, births=births, deaths=deaths)
print(s.summary())
variant: baseline
country: country ['Belgium' 'France' 'Germany'] (3)
gender: gender ['Male' 'Female'] (2)
time: time [2013 2014 2015 2016 2017] (5)
population: country, gender, time (3 x 2 x 5) [float64]
births: country, gender, time (3 x 2 x 5) [float64]
deaths: country, gender, time (3 x 2 x 5) [float64]
CheckedSession
The syntax to define a checked-session is a bit specific:
class MySession(CheckedSession):
# Variables can be declared in two ways:
# a) by specifying only the type of the variable (to be initialized later)
var1: Type
# b) by giving an initialization value.
# In that case, the type is deduced from the initialization value
var2 = initialization value
# Additionally, axes and dtype of Array variables can be constrained
# using the special type CheckedArray
arr1: CheckedArray([list, of, axes], dtype) = initialization value
Check the example below:
[6]:
class Demography(CheckedSession):
# (convention is to declare parameters (read-only objects) in capital letters)
# Declare 'VARIANT' parameter as of type string.
# 'VARIANT' will be initialized when a 'Demography' session will be created
VARIANT: str
# declare variables with an initialization value.
# Their type is deduced from their initialization value.
COUNTRY = Axis('country=Belgium,France,Germany')
GENDER = Axis('gender=Male,Female')
TIME = Axis('time=2013..2017')
population = zeros([COUNTRY, GENDER, TIME], dtype=int)
births = zeros([COUNTRY, GENDER, TIME], dtype=int)
# declare 'deaths' with constrained axes and dtype.
# Its type (Array), axes and dtype are not modifiable.
# It will be initialized with 0
deaths: CheckedArray([COUNTRY, GENDER, TIME], int) = 0
d = Demography(VARIANT='baseline')
print(d.summary())
VARIANT: baseline
deaths: country, gender, time (3 x 2 x 5) [int64]
COUNTRY: country ['Belgium' 'France' 'Germany'] (3)
GENDER: gender ['Male' 'Female'] (2)
TIME: time [2013 2014 2015 2016 2017] (5)
population: country, gender, time (3 x 2 x 5) [int64]
births: country, gender, time (3 x 2 x 5) [int64]
Loading and Dumping Sessions
One of the main advantages of grouping arrays, axes and groups in session objects is that you can load and save all of them in one shot. Like arrays, it is possible to associate metadata to a session. These can be saved and loaded in all file formats.
Loading Sessions (CSV, Excel, HDF5)
To load the items of a session, you have two options:
Instantiate a new session and pass the path to the Excel/HDF5 file or to the directory containing CSV files to the Session constructor:
[7]:
# create a new Session object and load all arrays, axes, groups and metadata
# from all CSV files located in the passed directory
csv_dir = get_example_filepath('demography_eurostat')
s = Session(csv_dir)
# create a new Session object and load all arrays, axes, groups and metadata
# stored in the passed Excel file
filepath_excel = get_example_filepath('demography_eurostat.xlsx')
s = Session(filepath_excel)
# create a new Session object and load all arrays, axes, groups and metadata
# stored in the passed HDF5 file
filepath_hdf = get_example_filepath('demography_eurostat.h5')
s = Session(filepath_hdf)
print(s.summary())
Metadata:
title: Demographic datasets for a small selection of countries in Europe
source: demo_jpan, demo_fasec, demo_magec and migr_imm1ctz tables from Eurostat
births: country, gender, time (3 x 2 x 5) [int32]
deaths: country, gender, time (3 x 2 x 5) [int32]
immigration: country, citizenship, gender, time (3 x 3 x 2 x 5) [int32]
population: country, gender, time (3 x 2 x 5) [int32]
population_5_countries: country, gender, time (5 x 2 x 5) [int32]
population_benelux: country, gender, time (3 x 2 x 5) [int32]
citizenship: citizenship ['Belgium' 'Luxembourg' 'Netherlands'] (3)
country: country ['Belgium' 'France' 'Germany'] (3)
country_benelux: country ['Belgium' 'Luxembourg' 'Netherlands'] (3)
gender: gender ['Male' 'Female'] (2)
time: time [2013 2014 2015 2016 2017] (5)
even_years: time[2014 2016] >> even_years (2)
odd_years: time[2013 2015 2017] >> odd_years (3)
Call the
loadmethod on an existing session and pass the path to the Excel/HDF5 file or to the directory containing CSV files as first argument:
[8]:
# create a session containing 3 axes, 2 groups and one array 'population'
filepath = get_example_filepath('population_only.xlsx')
s = Session(filepath)
print(s.summary())
population: country, gender, time (3 x 2 x 3) [int64]
[9]:
# call the load method on the previous session and add the 'births' and 'deaths' arrays to it
filepath = get_example_filepath('births_and_deaths.xlsx')
s.load(filepath)
print(s.summary())
population: country, gender, time (3 x 2 x 3) [int64]
births: country, gender, time (3 x 2 x 3) [int64]
deaths: country, gender, time (3 x 2 x 3) [int64]
The load method offers some options:
Using the
namesargument, you can specify which items to load:
[10]:
births_and_deaths_session = Session()
# use the names argument to only load births and deaths arrays
births_and_deaths_session.load(filepath_hdf, names=['births', 'deaths'])
print(births_and_deaths_session.summary())
Metadata:
title: Demographic datasets for a small selection of countries in Europe
source: demo_jpan, demo_fasec, demo_magec and migr_imm1ctz tables from Eurostat
births: country, gender, time (3 x 2 x 5) [int32]
deaths: country, gender, time (3 x 2 x 5) [int32]
Setting the
displayargument to True, theloadmethod will print a message each time a new item is loaded:
[11]:
s = Session()
# with display=True, the load method will print a message
# each time a new item is loaded
s.load(filepath_hdf, display=True)
opening /home/docs/checkouts/readthedocs.org/user_builds/larray/envs/latest/lib/python3.11/site-packages/larray/tests/data/demography_eurostat.h5
loading Array object births ... done
loading Array object deaths ... done
loading Array object immigration ... done
loading Array object population ... done
loading Array object population_5_countries ... done
loading Array object population_benelux ... done
loading Axis_Backward_Comp object citizenship ... done
loading Axis_Backward_Comp object country ... done
loading Axis_Backward_Comp object country_benelux ... done
loading Axis_Backward_Comp object gender ... done
loading Axis_Backward_Comp object time ... done
loading Group_Backward_Comp object even_years ... done
loading Group_Backward_Comp object odd_years ... done
Dumping Sessions (CSV, Excel, HDF5)
To save a session, you need to call the save method. The first argument is the path to a Excel/HDF5 file or to a directory if items are saved to CSV files:
[12]:
# save items of a session in CSV files.
# Here, the save method will create a 'demography' directory in which CSV files will be written
s.save('demography')
# save the session to an HDF5 file
s.save('demography.h5')
# save the session to an Excel file
s.save('demography.xlsx')
Note: Concerning the CSV and Excel formats, the metadata is saved in one Excel sheet (CSV file) named __metadata__(.csv). This sheet (CSV file) name cannot be changed.
The save method has several arguments:
Using the
namesargument, you can specify which items to save:
[13]:
# use the names argument to only save births and deaths arrays
s.save('demography.h5', names=['births', 'deaths'])
# load session saved in 'demography.h5' to see its content
Session('demography.h5').names
[13]:
['births', 'deaths']
By default, dumping a session to an Excel or HDF5 file will overwrite it. By setting the
overwriteargument to False, you can choose to update the existing Excel or HDF5 file:
[14]:
population = read_csv('./demography/population.csv')
pop_ses = Session([('population', population)])
# by setting overwrite to False, the destination file is updated instead of overwritten.
# The items already stored in the file but not present in the session are left intact.
# On the contrary, the items that exist in both the file and the session are completely overwritten.
pop_ses.save('demography.h5', overwrite=False)
# load session saved in 'demography.h5' to see its content
Session('demography.h5').names
[14]:
['births', 'deaths', 'population']
Setting the
displayargument to True, thesavemethod will print a message each time an item is dumped:
[15]:
# with display=True, the save method will print a message
# each time an item is dumped
s.save('demography.h5', display=True)
dumping births ... done
dumping deaths ... done
dumping immigration ... done
dumping population ... done
dumping population_5_countries ... done
dumping population_benelux ... done
dumping citizenship ... done
dumping country ... done
dumping country_benelux ... done
dumping gender ... done
dumping time ... done
dumping even_years ... done
dumping odd_years ... done
Exploring Content
To get the list of items names of a session, use the names shortcut (be careful that the list is sorted alphabetically and does not follow the internal order!):
[16]:
# load a session representing the results of a demographic model
filepath_hdf = get_example_filepath('demography_eurostat.h5')
s = Session(filepath_hdf)
# print the content of the session
print(s.names)
['births', 'citizenship', 'country', 'country_benelux', 'deaths', 'even_years', 'gender', 'immigration', 'odd_years', 'population', 'population_5_countries', 'population_benelux', 'time']
To get more information of items of a session, the summary will provide not only the names of items but also the list of labels in the case of axes or groups and the list of axes, the shape and the dtype in the case of arrays:
[17]:
# print the content of the session
print(s.summary())
Metadata:
title: Demographic datasets for a small selection of countries in Europe
source: demo_jpan, demo_fasec, demo_magec and migr_imm1ctz tables from Eurostat
births: country, gender, time (3 x 2 x 5) [int32]
deaths: country, gender, time (3 x 2 x 5) [int32]
immigration: country, citizenship, gender, time (3 x 3 x 2 x 5) [int32]
population: country, gender, time (3 x 2 x 5) [int32]
population_5_countries: country, gender, time (5 x 2 x 5) [int32]
population_benelux: country, gender, time (3 x 2 x 5) [int32]
citizenship: citizenship ['Belgium' 'Luxembourg' 'Netherlands'] (3)
country: country ['Belgium' 'France' 'Germany'] (3)
country_benelux: country ['Belgium' 'Luxembourg' 'Netherlands'] (3)
gender: gender ['Male' 'Female'] (2)
time: time [2013 2014 2015 2016 2017] (5)
even_years: time[2014 2016] >> even_years (2)
odd_years: time[2013 2015 2017] >> odd_years (3)
Selecting And Filtering Items
Session objects work like ordinary dict Python objects. To select an item, use the usual syntax <session_var>['<item_name>']:
[18]:
s['population']
[18]:
country gender\time 2013 2014 2015 2016 2017
Belgium Male 5472856 5493792 5524068 5569264 5589272
Belgium Female 5665118 5687048 5713206 5741853 5762455
France Male 31772665 32045129 32174258 32247386 32318973
France Female 33827685 34120851 34283895 34391005 34485148
Germany Male 39380976 39556923 39835457 40514123 40697118
Germany Female 41142770 41210540 41362080 41661561 41824535
A simpler way consists in the use the syntax <session_var>.<item_name>:
[19]:
s.population
[19]:
country gender\time 2013 2014 2015 2016 2017
Belgium Male 5472856 5493792 5524068 5569264 5589272
Belgium Female 5665118 5687048 5713206 5741853 5762455
France Male 31772665 32045129 32174258 32247386 32318973
France Female 33827685 34120851 34283895 34391005 34485148
Germany Male 39380976 39556923 39835457 40514123 40697118
Germany Female 41142770 41210540 41362080 41661561 41824535
Warning: The syntax session_var.item_name will work as long as you don’t use any special character like , ; : in the item’s name.
To return a new session with selected items, use the syntax <session_var>[list, of, item, names]:
[20]:
s_selected = s['population', 'births', 'deaths']
s_selected.names
[20]:
['births', 'deaths', 'population']
Warning: The same selection as above can be applied on a checked-session but the returned object is a normal session and NOT a checked-session. This means that you will loose all the benefits (autocomplete, protection on type, axes and dtype) of checked-sessions.
[21]:
d_selected = d['births', 'deaths']
# test if v_selected is a checked-session
print('is still a check-session?', isinstance(d_selected, CheckedSession))
#test if v_selected is a normal session
print('is now a normal session?', isinstance(d_selected, Session))
is still a check-session? False
is now a normal session? True
The filter method allows you to select all items of the same kind (i.e. all axes, or groups or arrays) or all items with names satisfying a given pattern:
[22]:
# select only arrays of a session
s.filter(kind=Array)
[22]:
Session(births, deaths, immigration, population, population_5_countries, population_benelux)
[23]:
# selection all items with a name starting with a letter between a and k
s.filter(pattern='[a-k]*')
[23]:
Session(births, deaths, immigration, citizenship, country, country_benelux, gender, even_years)
Warning: Using the filter() method on a checked-session will return a normal session and NOT a checked-session. This means that you will loose all the benefits (autocomplete, protection on type, axes and dtype) of checked-sessions.
[24]:
d_filtered = d.filter(pattern='[a-k]*')
# test if v_selected is a checked-session
print('is still a check-session?', isinstance(d_filtered, CheckedSession))
#test if v_selected is a normal session
print('is now a normal session?', isinstance(d_filtered, Session))
is still a check-session? False
is now a normal session? True
Iterating over Items
Like the built-in Python dict objects, Session objects provide methods to iterate over items:
[25]:
# iterate over item names
for key in s.keys():
print(key)
births
deaths
immigration
population
population_5_countries
population_benelux
citizenship
country
country_benelux
gender
time
even_years
odd_years
[26]:
# iterate over items
for value in s.values():
if isinstance(value, Array):
print(value.info)
else:
print(repr(value))
print()
title: Live births by mother's age and newborn's sex
source: table demo_fasec from Eurostat
3 x 2 x 5
country [3]: 'Belgium' 'France' 'Germany'
gender [2]: 'Male' 'Female'
time [5]: 2013 2014 2015 2016 2017
dtype: int32
memory used: 120 bytes
title: Deaths by age and sex
source: table demo_magec from Eurostat
3 x 2 x 5
country [3]: 'Belgium' 'France' 'Germany'
gender [2]: 'Male' 'Female'
time [5]: 2013 2014 2015 2016 2017
dtype: int32
memory used: 120 bytes
title: Immigration by age group, sex and citizenship
source: table migr_imm1ctz from Eurostat
3 x 3 x 2 x 5
country [3]: 'Belgium' 'Luxembourg' 'Netherlands'
citizenship [3]: 'Belgium' 'Luxembourg' 'Netherlands'
gender [2]: 'Male' 'Female'
time [5]: 2013 2014 2015 2016 2017
dtype: int32
memory used: 360 bytes
title: Population on 1 January by age and sex
source: table demo_pjan from Eurostat
3 x 2 x 5
country [3]: 'Belgium' 'France' 'Germany'
gender [2]: 'Male' 'Female'
time [5]: 2013 2014 2015 2016 2017
dtype: int32
memory used: 120 bytes
title: Population on 1 January by age and sex (Benelux + France + Germany)
source: table demo_pjan from Eurostat
5 x 2 x 5
country [5]: 'Belgium' 'France' 'Germany' 'Luxembourg' 'Netherlands'
gender [2]: 'Male' 'Female'
time [5]: 2013 2014 2015 2016 2017
dtype: int32
memory used: 200 bytes
title: Population on 1 January by age and sex (Benelux)
source: table demo_pjan from Eurostat
3 x 2 x 5
country [3]: 'Belgium' 'Luxembourg' 'Netherlands'
gender [2]: 'Male' 'Female'
time [5]: 2013 2014 2015 2016 2017
dtype: int32
memory used: 120 bytes
Axis(['Belgium', 'Luxembourg', 'Netherlands'], 'citizenship')
Axis(['Belgium', 'France', 'Germany'], 'country')
Axis(['Belgium', 'Luxembourg', 'Netherlands'], 'country')
Axis(['Male', 'Female'], 'gender')
Axis([2013, 2014, 2015, 2016, 2017], 'time')
time[2014, 2016] >> 'even_years'
time[2013, 2015, 2017] >> 'odd_years'
[27]:
# iterate over names and items
for key, value in s.items():
if isinstance(value, Array):
print(key, ':')
print(value.info)
else:
print(key, ':', repr(value))
print()
births :
title: Live births by mother's age and newborn's sex
source: table demo_fasec from Eurostat
3 x 2 x 5
country [3]: 'Belgium' 'France' 'Germany'
gender [2]: 'Male' 'Female'
time [5]: 2013 2014 2015 2016 2017
dtype: int32
memory used: 120 bytes
deaths :
title: Deaths by age and sex
source: table demo_magec from Eurostat
3 x 2 x 5
country [3]: 'Belgium' 'France' 'Germany'
gender [2]: 'Male' 'Female'
time [5]: 2013 2014 2015 2016 2017
dtype: int32
memory used: 120 bytes
immigration :
title: Immigration by age group, sex and citizenship
source: table migr_imm1ctz from Eurostat
3 x 3 x 2 x 5
country [3]: 'Belgium' 'Luxembourg' 'Netherlands'
citizenship [3]: 'Belgium' 'Luxembourg' 'Netherlands'
gender [2]: 'Male' 'Female'
time [5]: 2013 2014 2015 2016 2017
dtype: int32
memory used: 360 bytes
population :
title: Population on 1 January by age and sex
source: table demo_pjan from Eurostat
3 x 2 x 5
country [3]: 'Belgium' 'France' 'Germany'
gender [2]: 'Male' 'Female'
time [5]: 2013 2014 2015 2016 2017
dtype: int32
memory used: 120 bytes
population_5_countries :
title: Population on 1 January by age and sex (Benelux + France + Germany)
source: table demo_pjan from Eurostat
5 x 2 x 5
country [5]: 'Belgium' 'France' 'Germany' 'Luxembourg' 'Netherlands'
gender [2]: 'Male' 'Female'
time [5]: 2013 2014 2015 2016 2017
dtype: int32
memory used: 200 bytes
population_benelux :
title: Population on 1 January by age and sex (Benelux)
source: table demo_pjan from Eurostat
3 x 2 x 5
country [3]: 'Belgium' 'Luxembourg' 'Netherlands'
gender [2]: 'Male' 'Female'
time [5]: 2013 2014 2015 2016 2017
dtype: int32
memory used: 120 bytes
citizenship : Axis(['Belgium', 'Luxembourg', 'Netherlands'], 'citizenship')
country : Axis(['Belgium', 'France', 'Germany'], 'country')
country_benelux : Axis(['Belgium', 'Luxembourg', 'Netherlands'], 'country')
gender : Axis(['Male', 'Female'], 'gender')
time : Axis([2013, 2014, 2015, 2016, 2017], 'time')
even_years : time[2014, 2016] >> 'even_years'
odd_years : time[2013, 2015, 2017] >> 'odd_years'
Manipulating Checked Sessions
Note: this section only concerns objects declared in checked-sessions.
Let’s create a simplified version of the Demography checked-session we have defined above:
[28]:
class Demography(CheckedSession):
COUNTRY = Axis('country=Belgium,France,Germany')
GENDER = Axis('gender=Male,Female')
TIME = Axis('time=2013..2017')
population = zeros([COUNTRY, GENDER, TIME], dtype=int)
# declare the deaths array with constrained axes and dtype
deaths: CheckedArray([COUNTRY, GENDER, TIME], int) = 0
d = Demography()
print(d.summary())
deaths: country, gender, time (3 x 2 x 5) [int64]
COUNTRY: country ['Belgium' 'France' 'Germany'] (3)
GENDER: gender ['Male' 'Female'] (2)
TIME: time [2013 2014 2015 2016 2017] (5)
population: country, gender, time (3 x 2 x 5) [int64]
One of the specificities of checked-sessions is that the type of the contained objects is protected (it cannot change). Any attempt to assign a value of different type will raise an error:
[29]:
# The population variable was initialized with the zeros() function which returns an Array object.
# The declared type of the population variable is Array and is protected
d.population = Axis('population=child,teenager,adult,elderly')
TypeError: Error while assigning value to variable 'population':
Input should be an instance of Array. Got input value of type 'Axis'.
The death array has been declared as a CheckedArray. As a consequence, its axes are protected. Trying to assign a value with incompatible axes raises an error:
[30]:
AGE = Axis('age=0..100')
d.deaths = zeros([d.COUNTRY, AGE, d.GENDER, d.TIME])
ValueError: Error while assigning value to variable 'deaths':
Array 'deaths' was declared with axes {country, gender, time} but got array with axes {country, age, gender, time} (unexpected {age} axis)
The deaths array is also constrained by its declared dtype int. This means that if you try to assign a value of type float instead of int, the value will be converted to int if possible:
[31]:
d.deaths = 1.2
d.deaths
/home/docs/checkouts/readthedocs.org/user_builds/larray/envs/latest/lib/python3.11/site-packages/larray/core/array.py:8615: FutureWarning:
Setting a subset of an array with int64 dtype with a value with float dtype.
It will be converted to int64 like in previous larray versions but this is
not a safe operation (some information could be lost in the conversion).
If you want to keep doing this conversion and silence this warning, please
convert the value explicitly using value.astype(<target_array_type>).
This warning will become an error in a future version of larray.
res[:] = fill_value
[31]:
country gender\time 2013 2014 2015 2016 2017
Belgium Male 1 1 1 1 1
Belgium Female 1 1 1 1 1
France Male 1 1 1 1 1
France Female 1 1 1 1 1
Germany Male 1 1 1 1 1
Germany Female 1 1 1 1 1
or raise an error:
[32]:
d.deaths = 'undead'
/home/docs/checkouts/readthedocs.org/user_builds/larray/envs/latest/lib/python3.11/site-packages/larray/core/array.py:8615: FutureWarning:
Setting a subset of an array with int64 dtype with a value with str dtype.
It will be converted to int64 like in previous larray versions but this is
not a safe operation (some information could be lost in the conversion).
If you want to keep doing this conversion and silence this warning, please
convert the value explicitly using value.astype(<target_array_type>).
This warning will become an error in a future version of larray.
res[:] = fill_value
ValueError: Error while assigning value to variable 'deaths':
invalid literal for int() with base 10: 'undead'
It is possible to add a new variable after the checked-session has been initialized but in that case, a warning message is printed (in case you misspelled the name of variable while trying to modify it):
[33]:
# misspell population (forgot the 'a')
d.popultion = 0
/tmp/ipykernel_3115/1566890367.py:2: UserWarning: 'popultion' is not declared in 'Demography'
d.popultion = 0
Arithmetic Operations On Sessions
Session objects accept binary operations with a scalar:
[34]:
# get population, births and deaths in millions
s_div = s / 1e6
s_div.population
[34]:
country gender\time 2013 2014 2015 2016 2017
Belgium Male 5.472856 5.493792 5.524068 5.569264 5.589272
Belgium Female 5.665118 5.687048 5.713206 5.741853 5.762455
France Male 31.772665 32.045129 32.174258 32.247386 32.318973
France Female 33.827685 34.120851 34.283895 34.391005 34.485148
Germany Male 39.380976 39.556923 39.835457 40.514123 40.697118
Germany Female 41.14277 41.21054 41.36208 41.661561 41.824535
with an array (please read the documentation of the random.choice function first if you don’t know it):
[35]:
from larray import random
random_increment = random.choice([-1, 0, 1], p=[0.3, 0.4, 0.3], axes=s.population.axes) * 1000
random_increment
[35]:
country gender\time 2013 2014 2015 2016 2017
Belgium Male 0 0 1000 1000 -1000
Belgium Female 0 0 1000 0 0
France Male 1000 0 1000 0 1000
France Female -1000 1000 -1000 -1000 0
Germany Male 0 1000 -1000 -1000 0
Germany Female 1000 -1000 1000 0 1000
[36]:
# add some variables of a session by a common array
s_rand = s['population', 'births', 'deaths'] + random_increment
s_rand.population
[36]:
country gender\time 2013 2014 2015 2016 2017
Belgium Male 5472856 5493792 5525068 5570264 5588272
Belgium Female 5665118 5687048 5714206 5741853 5762455
France Male 31773665 32045129 32175258 32247386 32319973
France Female 33826685 34121851 34282895 34390005 34485148
Germany Male 39380976 39557923 39834457 40513123 40697118
Germany Female 41143770 41209540 41363080 41661561 41825535
with another session:
[37]:
# compute the difference between each array of the two sessions
s_diff = s - s_rand
s_diff.births
[37]:
country gender\time 2013 2014 2015 2016 2017
Belgium Male 0 0 -1000 -1000 1000
Belgium Female 0 0 -1000 0 0
France Male -1000 0 -1000 0 -1000
France Female 1000 -1000 1000 1000 0
Germany Male 0 -1000 1000 1000 0
Germany Female -1000 1000 -1000 0 -1000
Applying Functions On All Arrays
In addition to the classical arithmetic operations, the apply method can be used to apply the same function on all arrays. This function should take a single element argument and return a single value:
[38]:
# add the next year to all arrays
def add_next_year(array):
if 'time' in array.axes.names:
last_year = array.time.i[-1]
return array.append('time', 0, last_year + 1)
else:
return array
s_with_next_year = s.apply(add_next_year)
print('population array before calling apply:')
print(s.population)
print()
print('population array after calling apply:')
print(s_with_next_year.population)
population array before calling apply:
country gender\time 2013 2014 2015 2016 2017
Belgium Male 5472856 5493792 5524068 5569264 5589272
Belgium Female 5665118 5687048 5713206 5741853 5762455
France Male 31772665 32045129 32174258 32247386 32318973
France Female 33827685 34120851 34283895 34391005 34485148
Germany Male 39380976 39556923 39835457 40514123 40697118
Germany Female 41142770 41210540 41362080 41661561 41824535
population array after calling apply:
country gender\time 2013 2014 2015 2016 2017 2018
Belgium Male 5472856 5493792 5524068 5569264 5589272 0
Belgium Female 5665118 5687048 5713206 5741853 5762455 0
France Male 31772665 32045129 32174258 32247386 32318973 0
France Female 33827685 34120851 34283895 34391005 34485148 0
Germany Male 39380976 39556923 39835457 40514123 40697118 0
Germany Female 41142770 41210540 41362080 41661561 41824535 0
It is possible to pass a function with additional arguments:
[39]:
# add the next year to all arrays.
# Use the 'copy_values_from_last_year flag' to indicate
# whether to copy values from the last year
def add_next_year(array, copy_values_from_last_year):
if 'time' in array.axes.names:
last_year = array.time.i[-1]
value = array[last_year] if copy_values_from_last_year else 0
return array.append('time', value, last_year + 1)
else:
return array
s_with_next_year = s.apply(add_next_year, True)
print('population array before calling apply:')
print(s.population)
print()
print('population array after calling apply:')
print(s_with_next_year.population)
population array before calling apply:
country gender\time 2013 2014 2015 2016 2017
Belgium Male 5472856 5493792 5524068 5569264 5589272
Belgium Female 5665118 5687048 5713206 5741853 5762455
France Male 31772665 32045129 32174258 32247386 32318973
France Female 33827685 34120851 34283895 34391005 34485148
Germany Male 39380976 39556923 39835457 40514123 40697118
Germany Female 41142770 41210540 41362080 41661561 41824535
population array after calling apply:
country gender\time 2013 2014 2015 2016 2017 2018
Belgium Male 5472856 5493792 5524068 5569264 5589272 5589272
Belgium Female 5665118 5687048 5713206 5741853 5762455 5762455
France Male 31772665 32045129 32174258 32247386 32318973 32318973
France Female 33827685 34120851 34283895 34391005 34485148 34485148
Germany Male 39380976 39556923 39835457 40514123 40697118 40697118
Germany Female 41142770 41210540 41362080 41661561 41824535 41824535
It is also possible to apply a function on non-Array objects of a session. Please refer the documentation of the apply method.
Comparing Sessions
Being able to compare two sessions may be useful when you want to compare two different models expected to give the same results or when you have updated your model and want to see what are the consequences of the recent changes.
Session objects provide the two methods to compare two sessions: equals and element_equals:
The
equalsmethod will return True if all items from both sessions are identical, False otherwise.The
element_equalsmethod will compare items of two sessions one by one and return an array of boolean values.
[40]:
# load a session representing the results of a demographic model
filepath_hdf = get_example_filepath('demography_eurostat.h5')
s = Session(filepath_hdf)
# create a copy of the original session
s_copy = s.copy()
[41]:
# 'element_equals' compare arrays one by one
s.element_equals(s_copy)
[41]:
name births deaths ... time even_years odd_years
True True ... True True True
[42]:
# 'equals' returns True if all items of the two sessions have exactly the same items
s.equals(s_copy)
[42]:
True
[43]:
# slightly modify the 'population' array for some labels combination
s_copy.population += random_increment
[44]:
# the 'population' array is different between the two sessions
s.element_equals(s_copy)
[44]:
name births deaths ... time even_years odd_years
True True ... True True True
[45]:
# 'equals' returns False if at least one item of the two sessions are different in values or axes
s.equals(s_copy)
[45]:
False
[46]:
# reset the 'copy' session as a copy of the original session
s_copy = s.copy()
# add an array to the 'copy' session
s_copy.gender_ratio = s_copy.population.ratio('gender')
[47]:
# the 'gender_ratio' array is not present in the original session
s.element_equals(s_copy)
[47]:
name births deaths ... even_years odd_years gender_ratio
True True ... True True False
[48]:
# 'equals' returns False if at least one item is not present in the two sessions
s.equals(s_copy)
[48]:
False
The == operator return a new session with boolean arrays with elements compared element-wise:
[49]:
# reset the 'copy' session as a copy of the original session
s_copy = s.copy()
# slightly modify the 'population' array for some labels combination
s_copy.population += random_increment
[50]:
s_check_same_values = s == s_copy
s_check_same_values.population
[50]:
country gender\time 2013 2014 2015 2016 2017
Belgium Male True True False False False
Belgium Female True True False True True
France Male False True False True False
France Female False False False False True
Germany Male True False False False True
Germany Female False False False True False
This also works for axes and groups:
[51]:
s_check_same_values.time
[51]:
time 2013 2014 2015 2016 2017
True True True True True
The != operator does the opposite of == operator:
[52]:
s_check_different_values = s != s_copy
s_check_different_values.population
[52]:
country gender\time 2013 2014 2015 2016 2017
Belgium Male False False True True True
Belgium Female False False True False False
France Male True False True False True
France Female True True True True False
Germany Male False True True True False
Germany Female True True True False True
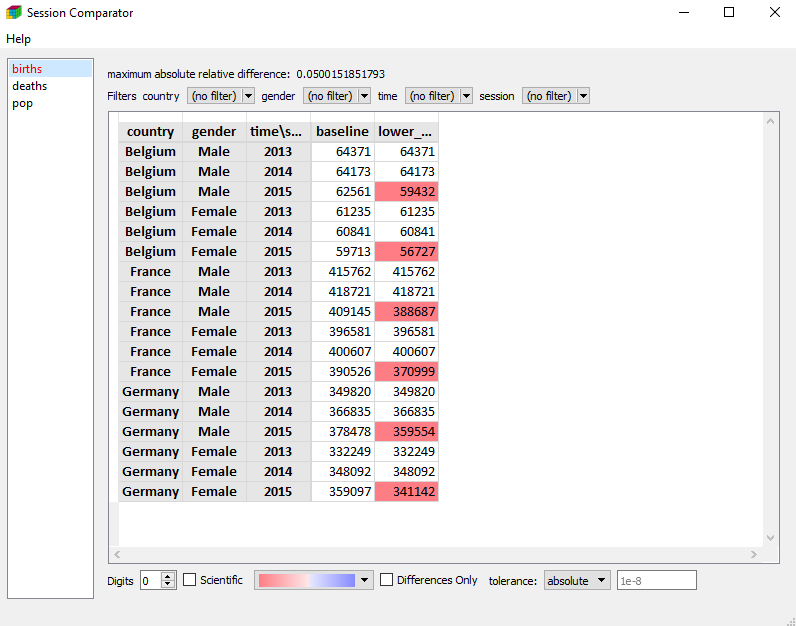
A more visual way is to use the compare function which will open the Editor.
compare(s, s_alternative, names=['baseline', 'lower_birth_rate'])