Interactive online version:
![]()
Getting Started
The purpose of the present Getting Started section is to give a quick overview of the main objects and features of the LArray library. To get a more detailed presentation of all capabilities of LArray, read the next sections of the tutorial.
The API Reference section of the documentation give you the list of all objects, methods and functions with their individual documentation and examples.
To use the LArray library, the first thing to do is to import it:
[2]:
from larray import *
To know the version of the LArray library installed on your machine, type:
[3]:
from larray import __version__
__version__
[3]:
'0.35.2'
Warning: The tutorial is generated from Jupyter notebooks which work in the “interactive” mode (like in the LArray Editor console). In the interactive mode, there is no need to use the print() function to display the content of a variable. Simply writing its name is enough. The same remark applies for the returned value of an expression. In a Python script (file with .py extension), you always need to use the print() function to display the content of a variable or the value returned by a function or an expression.
[4]:
s = 1 + 2
# In the interactive mode, there is no need to use the print() function
# to display the content of the variable 's'.
# Simply typing 's' is enough
s
[4]:
3
[5]:
# In the interactive mode, there is no need to use the print() function
# to display the result of an expression
1 + 2
[5]:
3
Create an array
Working with the LArray library mainly consists of manipulating Array data structures. They represent N-dimensional labelled arrays and are composed of raw data (NumPy ndarray), axes and optionally some metadata.
An Axis object represents a dimension of an array. It contains a list of labels and has a name. They are several ways to create an axis:
[6]:
# create an axis using one string
age = Axis('age=0-9,10-17,18-66,67+')
# labels generated using the special syntax start..end
time = Axis('time=2015..2017')
# labels given as a list
gender = Axis(['female', 'male'], 'gender')
age, gender, time
[6]:
(Axis(['0-9', '10-17', '18-66', '67+'], 'age'),
Axis(['female', 'male'], 'gender'),
Axis([2015, 2016, 2017], 'time'))
Warning: When using the string syntax "axis_name=list,of,labels" or "axis_name=start..end", LArray will automatically infer the type of labels. For example, age = Axis("age=0..100") will create an age axis with labels of type int. Mixing numbers with letters or special characters like + will create an axis with labels of type str instead of int. For example, age = Axis("age=0..98,99+") will create an age axis with labels of type str instead of int!
The labels allow to select subsets and to manipulate the data without working with the positions of array elements directly.
To create an array from scratch, you need to supply data and axes:
[7]:
# define some data. This is the belgian population (in thousands). Source: eurostat.
data = [[[633, 635, 634],
[663, 665, 664]],
[[484, 486, 491],
[505, 511, 516]],
[[3572, 3581, 3583],
[3600, 3618, 3616]],
[[1023, 1038, 1053],
[756, 775, 793]]]
# create an Array object
population = Array(data, axes=[age, gender, time])
population
[7]:
age gender\time 2015 2016 2017
0-9 female 633 635 634
0-9 male 663 665 664
10-17 female 484 486 491
10-17 male 505 511 516
18-66 female 3572 3581 3583
18-66 male 3600 3618 3616
67+ female 1023 1038 1053
67+ male 756 775 793
You can optionally attach some metadata to an array:
[8]:
# attach some metadata to the population array
population.meta.title = 'population by age, gender and year'
population.meta.source = 'Eurostat'
# display metadata
population.meta
[8]:
title: population by age, gender and year
source: Eurostat
To get a short summary of an array, type:
[9]:
# Array summary: metadata + dimensions + description of axes
population.info
[9]:
title: population by age, gender and year
source: Eurostat
4 x 2 x 3
age [4]: '0-9' '10-17' '18-66' '67+'
gender [2]: 'female' 'male'
time [3]: 2015 2016 2017
dtype: int64
memory used: 192 bytes
To get the axes of an array, type:
[10]:
population.axes
[10]:
AxisCollection([
Axis(['0-9', '10-17', '18-66', '67+'], 'age'),
Axis(['female', 'male'], 'gender'),
Axis([2015, 2016, 2017], 'time')
])
It is also possible to extract one axis belonging to an array using its name:
[11]:
# extract the 'time' axis belonging to the 'population' array
time = population.time
time
[11]:
Axis([2015, 2016, 2017], 'time')
Create an array filled with predefined values
Arrays filled with predefined values can be generated through dedicated functions:
zeros: creates an array filled with 0ones: creates an array filled with 1full: creates an array filled with a given valuesequence: creates an array by sequentially applying modifications to the array along axis.ndtest: creates a test array with increasing numbers as data
[12]:
zeros([age, gender])
[12]:
age\gender female male
0-9 0.0 0.0
10-17 0.0 0.0
18-66 0.0 0.0
67+ 0.0 0.0
[13]:
ones([age, gender])
[13]:
age\gender female male
0-9 1.0 1.0
10-17 1.0 1.0
18-66 1.0 1.0
67+ 1.0 1.0
[14]:
full([age, gender], fill_value=10.0)
[14]:
age\gender female male
0-9 10.0 10.0
10-17 10.0 10.0
18-66 10.0 10.0
67+ 10.0 10.0
[15]:
# With initial=1.0 and inc=0.5, we generate the sequence 1.0, 1.5, 2.0, 2.5, 3.0, ...
sequence(age, initial=1.0, inc=0.5)
[15]:
age 0-9 10-17 18-66 67+
1.0 1.5 2.0 2.5
[16]:
ndtest([age, gender])
[16]:
age\gender female male
0-9 0 1
10-17 2 3
18-66 4 5
67+ 6 7
Save/Load an array
The LArray library offers many I/O functions to read and write arrays in various formats (CSV, Excel, HDF5). For example, to save an array in a CSV file, call the method to_csv:
[17]:
# save our population array to a CSV file
population.to_csv('population_belgium.csv')
The content of the CSV file is then:
age,gender\time,2015,2016,2017
0-9,female,633,635,634
0-9,male,663,665,664
10-17,female,484,486,491
10-17,male,505,511,516
18-66,female,3572,3581,3583
18-66,male,3600,3618,3616
67+,female,1023,1038,1053
67+,male,756,775,793
Note: In CSV or Excel files, the last dimension is horizontal and the names of the last two dimensions are separated by a backslash .
To load a saved array, call the function read_csv:
[18]:
population = read_csv('population_belgium.csv')
population
[18]:
age gender\time 2015 2016 2017
0-9 female 633 635 634
0-9 male 663 665 664
10-17 female 484 486 491
10-17 male 505 511 516
18-66 female 3572 3581 3583
18-66 male 3600 3618 3616
67+ female 1023 1038 1053
67+ male 756 775 793
Other input/output functions are described in the Input/Output section of the API documentation.
Selecting a subset
To select an element or a subset of an array, use brackets [ ]. In Python we usually use the term indexing for this operation.
Let us start by selecting a single element:
[19]:
population['67+', 'female', 2017]
[19]:
1053
Labels can be given in arbitrary order:
[20]:
population[2017, 'female', '67+']
[20]:
1053
When selecting a larger subset the result is an array:
[21]:
population['female']
[21]:
age\time 2015 2016 2017
0-9 633 635 634
10-17 484 486 491
18-66 3572 3581 3583
67+ 1023 1038 1053
When selecting several labels for the same axis, they must be given as a list (enclosed by [ ])
[22]:
population['female', ['0-9', '10-17']]
[22]:
age\time 2015 2016 2017
0-9 633 635 634
10-17 484 486 491
You can also select slices, which are all labels between two bounds (we usually call them the start and stop bounds). Specifying the start and stop bounds of a slice is optional: when not given, start is the first label of the corresponding axis, stop the last one:
[23]:
# in this case '10-17':'67+' is equivalent to ['10-17', '18-66', '67+']
population['female', '10-17':'67+']
[23]:
age\time 2015 2016 2017
10-17 484 486 491
18-66 3572 3581 3583
67+ 1023 1038 1053
[24]:
# :'18-66' selects all labels between the first one and '18-66'
# 2017: selects all labels between 2017 and the last one
population[:'18-66', 2017:]
[24]:
age gender\time 2017
0-9 female 634
0-9 male 664
10-17 female 491
10-17 male 516
18-66 female 3583
18-66 male 3616
Note: Contrary to slices on normal Python lists, the stop bound is included in the selection.
Warning: Selecting by labels as above only works as long as there is no ambiguity. When several axes have some labels in common and you do not specify explicitly on which axis to work, it fails with an error ending with something like: ValueError: <somelabel> is ambiguous (valid in <axis1>, <axis2>)
For example, imagine you need to work with an ‘immigration’ array containing two axes sharing some common labels:
[25]:
country = Axis(['Belgium', 'Netherlands', 'Germany'], 'country')
citizenship = Axis(['Belgium', 'Netherlands', 'Germany'], 'citizenship')
immigration = ndtest((country, citizenship, time))
immigration
[25]:
country citizenship\time 2015 2016 2017
Belgium Belgium 0 1 2
Belgium Netherlands 3 4 5
Belgium Germany 6 7 8
Netherlands Belgium 9 10 11
Netherlands Netherlands 12 13 14
Netherlands Germany 15 16 17
Germany Belgium 18 19 20
Germany Netherlands 21 22 23
Germany Germany 24 25 26
If we try to get the number of Belgians living in the Netherlands for the year 2017, we might try something like:
immigration['Netherlands', 'Belgium', 2017]
… but we receive back a volley of insults:
[some long error message ending with the line below]
[...]
ValueError: Netherlands is ambiguous (valid in country, citizenship)
In that case, we have to specify explicitly which axes the ‘Netherlands’ and ‘Belgium’ labels we want to select belong to:
[26]:
immigration[country['Netherlands'], citizenship['Belgium'], 2017]
[26]:
11
Aggregation
The LArray library includes many aggregations methods: sum, mean, min, max, std, var, …
For example, assuming we still have an array in the population variable:
[27]:
population
[27]:
age gender\time 2015 2016 2017
0-9 female 633 635 634
0-9 male 663 665 664
10-17 female 484 486 491
10-17 male 505 511 516
18-66 female 3572 3581 3583
18-66 male 3600 3618 3616
67+ female 1023 1038 1053
67+ male 756 775 793
We can sum along the ‘gender’ axis using:
[28]:
population.sum(gender)
[28]:
age\time 2015 2016 2017
0-9 1296 1300 1298
10-17 989 997 1007
18-66 7172 7199 7199
67+ 1779 1813 1846
Or sum along both ‘age’ and ‘gender’:
[29]:
population.sum(age, gender)
[29]:
time 2015 2016 2017
11236 11309 11350
It is sometimes more convenient to aggregate along all axes except some. In that case, use the aggregation methods ending with _by. For example:
[30]:
population.sum_by(time)
[30]:
time 2015 2016 2017
11236 11309 11350
Groups
A Group object represents a subset of labels or positions of an axis:
[31]:
children = age['0-9', '10-17']
children
[31]:
age['0-9', '10-17']
It is often useful to attach them an explicit name using the >> operator:
[32]:
working = age['18-66'] >> 'working'
working
[32]:
age['18-66'] >> 'working'
[33]:
nonworking = age['0-9', '10-17', '67+'] >> 'nonworking'
nonworking
[33]:
age['0-9', '10-17', '67+'] >> 'nonworking'
Still using the same population array:
[34]:
population
[34]:
age gender\time 2015 2016 2017
0-9 female 633 635 634
0-9 male 663 665 664
10-17 female 484 486 491
10-17 male 505 511 516
18-66 female 3572 3581 3583
18-66 male 3600 3618 3616
67+ female 1023 1038 1053
67+ male 756 775 793
Groups can be used in selections:
[35]:
population[working]
[35]:
gender\time 2015 2016 2017
female 3572 3581 3583
male 3600 3618 3616
[36]:
population[nonworking]
[36]:
age gender\time 2015 2016 2017
0-9 female 633 635 634
0-9 male 663 665 664
10-17 female 484 486 491
10-17 male 505 511 516
67+ female 1023 1038 1053
67+ male 756 775 793
or aggregations:
[37]:
population.sum(nonworking)
[37]:
gender\time 2015 2016 2017
female 2140 2159 2178
male 1924 1951 1973
When aggregating several groups, the names we set above using >> determines the label on the aggregated axis. Since we did not give a name for the children group, the resulting label is generated automatically :
[38]:
population.sum((children, working, nonworking))
[38]:
age gender\time 2015 2016 2017
0-9,10-17 female 1117 1121 1125
0-9,10-17 male 1168 1176 1180
working female 3572 3581 3583
working male 3600 3618 3616
nonworking female 2140 2159 2178
nonworking male 1924 1951 1973
Warning: Mixing slices and individual labels inside the [ ] will generate several groups (a tuple of groups) instead of a single group. If you want to create a single group using both slices and individual labels, you need to use the .union() method (see below).
[39]:
age_100 = Axis('age=0..100')
# mixing slices and individual labels leads to the creation of several groups (a tuple of groups)
age_100[0:10, 20, 30, 40]
[39]:
(age[0:10], age[20], age[30], age[40])
[40]:
# the union() method allows to mix slices and individual labels to create a single group
age_100[0:10].union(age_100[20, 30, 40])
[40]:
age[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30, 40].set()
Grouping arrays in a Session
Variables (arrays) may be grouped in Session objects. A session is an ordered dict-like container with special I/O methods:
[41]:
population = zeros([age, gender, time])
births = zeros([age, gender, time])
deaths = zeros([age, gender, time])
# create a session containing the arrays of the model
demography_session = Session(population=population, births=births, deaths=deaths)
# get an array (option 1)
demography_session['population']
# get an array (option 2)
demography_session.births
# modify an array
demography_session.deaths['male'] = 1
# add an array
demography_session.foreigners = zeros([age, gender, time])
# displays names of arrays contained in the session
# (in alphabetical order)
demography_session.names
[41]:
['births', 'deaths', 'foreigners', 'population']
One of the main interests of using sessions is to save and load many arrays at once:
[42]:
# dump all arrays contained in demography_session in one HDF5 file
demography_session.save('demography.h5')
# load all arrays saved in the HDF5 file 'demography.h5' and store them in the 'demography_session' variable
demography_session = Session('demography.h5')
However, development tools like PyCharm do not provide autocomplete for objects in Session objects.
Autocomplete is the feature in which development tools try to predict the variable or function a user intends to enter after only a few characters have been typed (like word completion in cell phones).
Another way to group objects of a model is to use CheckedSession. The CheckedSession provide the same methods than Session but enable the autocomplete feature on objects it contains.
For more details about Session and CheckedSession, see the Working With Sessions section of the tutorial.
To get the list of methods belonging to the Session and CheckedSession ojects, check the corresponding section in the API Reference.
Graphical User Interface (Editor)
The LArray project provides an optional package called larray-editor allowing users to explore and edit arrays through a graphical interface.
The view() function displays the content of (an) array(s) in a graphical user interface in read-only mode.
For instance, the statement
view(population)
will open a new window showing the values and axes of the ‘population’ array.
The statement
view(demography_session)
will show all arrays contained in the ‘demography_session’.
A session can be directly loaded from a file
view('demography.h5')
Calling
view()
with no passed argument creates a session with all existing arrays from the current namespace and shows its content.
Notes:
Calling
view()will block the execution of the rest of code until the graphical user interface is closed!The larray-editor tool is automatically available when installing the larrayenv metapackage from conda.
To open the user interface in edit mode, call the edit() function instead.
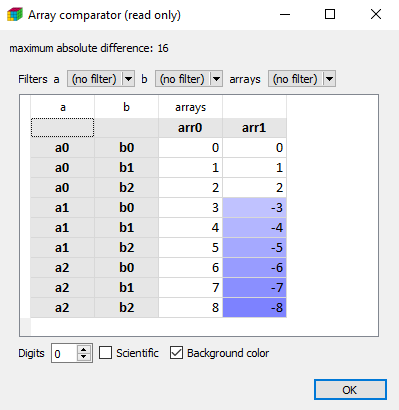
Finally, you can also visually compare two arrays or sessions using the compare() function:
arr0 = ndtest((3, 3))
arr1 = ndtest((3, 3))
arr1[['a1', 'a2']] = -arr1[['a1', 'a2']]
compare(arr0, arr1)
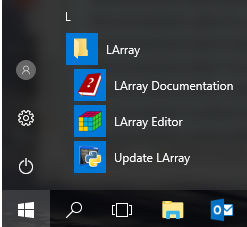
For Windows Users
Installing the larray-editor package on Windows will create a LArray menu in the Windows Start Menu. This menu contains:
a shortcut to open the documentation of the last stable version of the library
a shortcut to open the graphical interface in edit mode.
a shortcut to update
larrayenv.
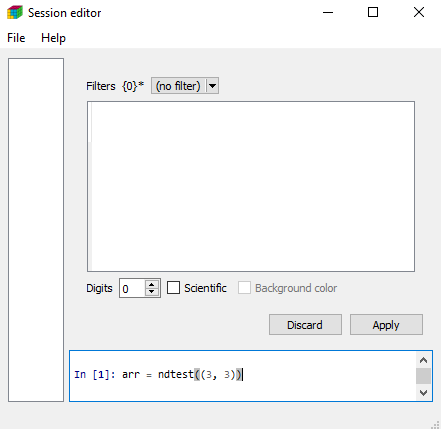
Once the graphical interface is open, all LArray objects and functions are directly accessible. No need to start by from larray import *.